The Harvest replicator will distribute copies of a Broker's database to replicas running throughout the Internet. Replication distributes the server load on a Broker, improving query performance and availability, and the replicator attempts to minimize network traffic and server workload when propagating updates.
The replicator manages a single directory tree of files. One site must be designated as the master copy. Updates to the master copy propagate to all other replicas and the master copy eventually overwrites any local changes made at individual replicas. It is possible to configure a replicated collection so that a different master copies manages separate sub-trees, to distribute the responsibility of (gathering and) managing a large collection. Each replicated collection is exported through a (single or possibly hierarchically nested) replication group. When a replica joins a replication group, it begins to fill with data. The right to join a replication group is managed by an access control list. If a replication group grows to hundreds or thousands of members, a new group can be created to ease management. This arrangement is illustrated in Figure 4.
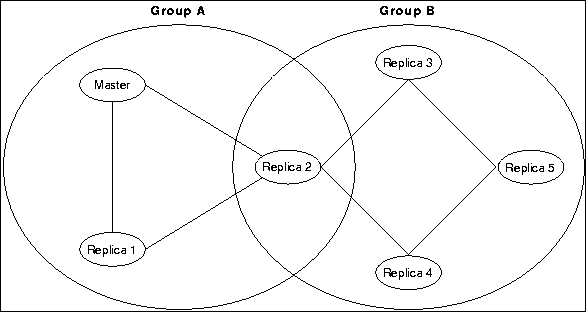
Figure 4: Replicator System Overview
The Harvest replicator consists of four components:
The replication system design is discussed in more depth in [8].